![]()
Intentando probar la v(ALÍA) de ALIA
El Gobierno de España, en colaboración con el Barcelona Supercomputing Center (BSC), ha lanzado ALIA, un modelo de lenguaje masivo (LLM) enfocado en el español y las lenguas cooficiales, que está disponible en Huggingface. Tras probarlo, aquí te cuento mis impresiones.
Un paso adelante en la IA en español
Como alguien que ha trabajado en el pasado con el BSC en el proyecto TANGO: Transparent heterogeneous hardware Architecture deployment for eNergy Gain in Operation, puedo decir que siempre han estado a la vanguardia en tecnologías del lenguaje e inteligencia artificial. ALIA es un ejemplo más de su compromiso con el desarrollo de herramientas para nuestra lengua, financiado eso sí, por el Gobierno de España.
Probando la “vALíA” de ALIA
He puesto a prueba ALIA para ver si cumple con su propuesta de valor. Aquí te dejo mis conclusiones:
- Entrenamiento en español: ALIA destaca por estar entrenado con un gran volumen de datos en español y lenguas cooficiales. Esto le da una ventaja a la hora de entender el contexto y los matices de nuestro idioma.
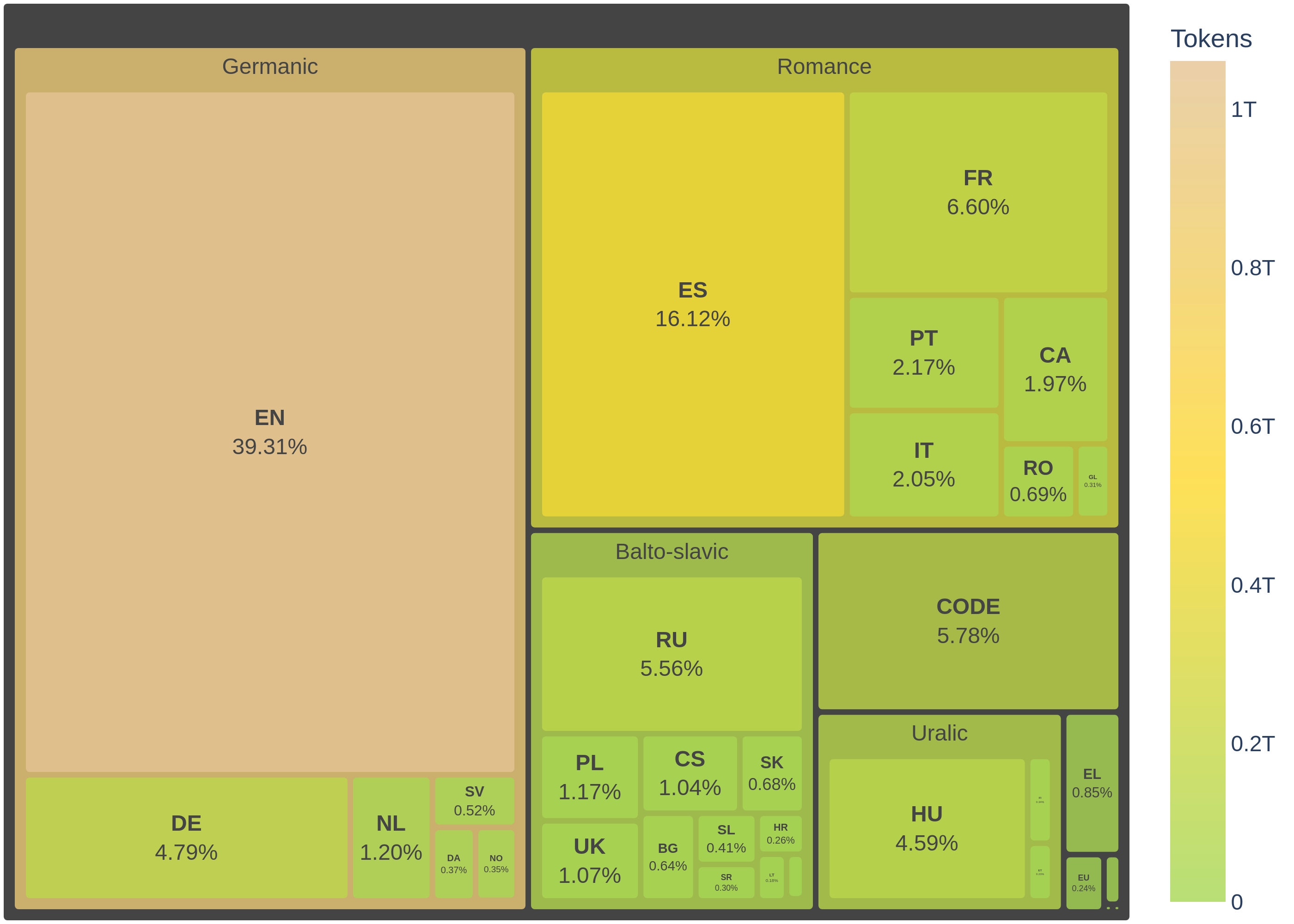
- Pruebas de rendimiento: He realizado diversas pruebas para evaluar la capacidad de ALIA para entender el contexto en español. Los resultados han sido variados, con algunas respuestas muy buenas y otras mejorables.
- Limitaciones: ALIA aún tiene algunas limitaciones, como un contexto de 4,096 tokens, que se queda corto comparado con otros modelos. Tampoco cuenta con capacidades como “Tool Calling”, “Structured Output”, ni “Reasoning”.
- “Guardrails”: He intentado poner a prueba las restricciones éticas de ALIA, con resultados diversos. Que pueden “traer cola”.
Pruebas realizadas
- Entendimiento del contexto: He realizado pruebas para evaluar la capacidad de ALIA para entender el contexto en español, desde el nivel léxico hasta el cultural.
- Generación de código: He probado la capacidad de ALIA para generar código Python en español, con resultados similares a otros modelos como ChatGPT y Gemini.
- Análisis de textos largos: He puesto a prueba la capacidad de ALIA para analizar textos largos en español, con resultados mejorables.
- “Guardrails”: He intentado engañar al sistema para ver cómo reacciona ante preguntas delicadas, con resultados variados.
Espero poder darle formato a las pruebas realizadas, así como poder llevar a cabo algunas más, y poder sacar un nuevo post con más detalles.
Conclusiones
ALIA es un modelo que tiene mucho margen de mejora, pero es un primer paso. Lo importante es empezar a andar y a ofrecer múltiples soluciones.
Ahora mismo no creo que esté al nivel de modelos masivos open source como los de Llama, Gemini, Phi, Qwen o Deepseek-R1, pero es un paso interesante.
Me gustaría que un equipo con los medios pudiera dedicar tiempo y esfuerzo a reforzar los modelos Españoles, y llevar a cabo el entrenamiento de un modelo con técnicas de “DISTILLATION” de Modelos “más inteligentes” en ALIA, o también poder reforzar mediante las técnicas propuestas por la Universidad de Stanford en el paper (s1: Simpletest-timescaling) que mejoran en rendimiento modelos como Deepseek-R1 con entrenamiento mucho menos costosos.
Habrá que seguir probándolo a medida que se vaya desarrollando.
¿Has probado ALIA? ¿Qué te ha parecido? ¡Cuéntame en los comentarios!